Refactoring
Refactoring is the process of making changes to the code to improve the internal software quality, without making any changes to the functionality of the software. Typically, we use refactoring to improve the design, analyzability, testability, and maintainability of our software.
For example, in the Analyzability unit, we turned this:
public List<int[]> asdfasdf(){List<int[]> dfghdfgh=new ArrayList<>();for(int[] ouertioert:kjsdfgklkjsdfg){if(ouertioert[0]==4)dfghdfgh.add(ouertioert);}return dfghdfgh;}
Into this:
public List<Cell> getFlaggedCells() {
List<Cell> flaggedCells = new ArrayList<>();
for (Cell cell : gameGrid.getCells()) {
if (cell.isFlagged()) {
flaggedCells.add(cell);
}
}
return flaggedCells;
}
This wouldn’t change the external behavior of our program, but it would make the code more understandable and more tolerant to implementation changes.
- Refactoring
Acknowledgement
Most of the material in this unit is derived from:
-
Clean Code: A Handbook of Agile Software Craftsmanship by Robert C. Martin, a book that I highly recommend and dramatically improved my own outlook on designing and writing software.
-
Refactoring.Guru - a great and highly recommended website for thinking about refactoring and software design. We will reference this website again, especially during the Design Patterns module.
Code Quality
As we noted in the last unit, no one writes easily understandable/changeable code the first time every time! We should always view the first pass of development (making the feature work) as a rough draft. When writing any paper, the rough draft requires editing, rewording, restructuring, etc. in order to produce a clean paper. We aren’t done when we finish the rough draft. We’re done when we’ve polished it and cleaned it up into the final draft!
Refactoring is the process by which we are editing our code to improve its maintainability! And it is a vital step in keeping our code maintainable and understandable!
Testing and Refactoring
Existing regression tests are vital for refactoring. When we refactor code, we want to ensure that we are not changing the external behavior of our software, only the internal code to improve maintainability. As such, it is vital to ensure that we have tests that correctly test the intended behavior of our code before we begin adjusting it. If we have been practicing TDD, then all of our tests should already be written for us.
These tests are the scaffolding that allow us to remodel our code. If we don’t have tests in place, we cannot evaluate if our changes are successfully preserving the external behavior of our software. With those tests, however, we can always be confident that we are ensuring external behavior is maintained. If we break external behavior, and cannot easily fix it, we can always roll back to the previous commit before we began refactoring.
Refactoring in IntelliJ
IntelliJ offers very strong refactoring tools. Never use find and replace, always Refactor
IntelliJ is great at renaming variables, functions, and class names. By using the automatic refactoring tools, it will update all references to the variable, function, or class for you throughout your project and your tests! It’s going to be smarter and faster than Find and Replace and is just as easy to use!
Extract constants
In IntelliJ, we can extract raw values into named constant values to improve code readability. For instance, take this code that might exist in the game Wordle
public void setAnswer(String answer) {
if (answer.length() != 5) {
throw new IllegalArgumentException("Invalid Wordle Answer: " + answer);
}
this.answer = answer;
}
By right-clicking on the 5, and going to Refactor -> Extract Constant, we can replace it with
public void setAnswer(String answer) {
if (answer.length() != WORDLE_WORD_LENGTH) {
throw new IllegalArgumentException("Invalid Wordle Answer: " + answer);
}
this.answer = answer;
}
Additionally, we can replace the number 5 in our code wherever it relates to the acceptable length of a word in the game wordle with this same constant.
Renaming Identifiers
Variables, functions, and constants can be easily renamed via refactoring. Simply right-click on an identifier name, Refactor->Rename, and type the new name.
Personally, renaming variables and functions is the most common refactoring that I do. I am constantly asking myself, “Is this the best name?” If I ever am reading over my old code and have any doubt whatsoever what the purpose of a variable or function is, my first step is always to rename it to ensure the name is the best it can be.
You should never use find-and-replace for this. This is because the existing name of the variable or function you are renaming may be a subset of another name. For example, if you have a variable named x, you should almost certainly rename it (though it can be acceptable in some limited contexts like coordinate systems). However, the letter x is very likely to appear elsewhere in your code.
Renaming identifiers is arguably the easiest refactoring tool, but it is also extremely useful, as good and intent-communicating function and variable names are the lifeblood of clean, readable code.
Renaming Classes
Similar to renaming other identifiers, we can also rename classes. Simply right-click on the class-name, Refactor-> Rename. Just be aware that renaming a public class also renames the file it is stored in.
Don’t be afraid to rename classes to make them simpler! For example, I once had a class called ArgumentsHandler
public class ArgumentsHandler {
private String[] args;
public ArgumentsHandler(String[] args) {
this.args = args;
}
public void processArguments() {
...
}
}
Until I realized: “The purpose of this class is to model and encapsulate the arguments. I can just call it Arguments”
So I renamed the class:
public class Arguments {
private String[] args;
public Arguments(String[] args) {
this.args = args;
}
public void processArguments() {
...
}
}
Moving classes between packages
We can move classes between packages with ease using IntelliJ. Simply click and drag the class in the Project Explorer into the package. IntelliJ will ensure that classes that rely on the class you move are updated to import the class if it is no longer in the same package. IntelliJ will even be smart enough to move your Test class for the class you moved to a parallel package in the Test directory (provided the name of the Test class file is [ClassName]Test.java)
Change Signature
Look at the following class:
public class Tabulator {
private Map<String, Integer> voteTotals = new HashMap<>();
public void addVotesToCandidate(String candidate, int votes) {
if (voteTotals.containsKey(candidate)) {
int currentVotes = voteTotals.get(candidate);
voteTotals.put(candidate, currentVotes + votes);
} else {
voteTotals.put(candidate, votes);
}
}
}
Consider the function addVotesToCandidate. Specifically, the order of the arguments. It may seem backwards. This is because our function name has the word Votes (the number of votes) before the word Candidate. However, we don’t just want to change the order manually. If we did that, everywhere that our function is used would now have a syntax error. Instead, we right-click on our method and use Refactor->Change Signature. Then, we simply move the first argument (String candidate) Down:
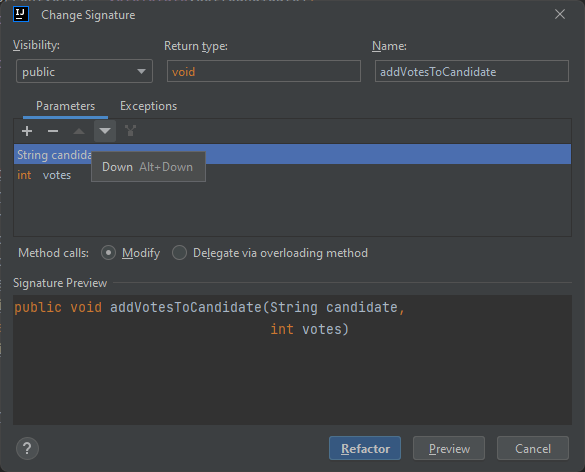
…and hit “Refactor”. IntelliJ will then update our method and change the arguments order anywhere we call the method!
public class Tabulator {
private Map<String, Integer> voteTotals = new HashMap<>();
public void addVotesToCandidate(int votes, String candidate) {
if (voteTotals.containsKey(candidate)) {
int currentVotes = voteTotals.get(candidate);
voteTotals.put(candidate, currentVotes + votes);
} else {
voteTotals.put(candidate, votes);
}
}
}
Other Refactoring Techniques
Not all refactoring can be easily done automatically like the above, and will require some manual effort. However, it is worth learning some basic refactoring techniques that you can do manually and at times with the help of IntelliJ. Note that this list are ones that I find particularly useful and also easy to describe. There are many, many more Refactoring Techniques. Refactoring Guru has a particularly good list of refactoring techniques.
Replace Array with Object
We covered this example with the Cell object in our Minesweeper example. Namely, converting this:
public List<int[]> getFlaggedCells() {
List<int[]> flaggedCells = new ArrayList<>();
for (int[] cell : gameGrid) {
if (cell[CELL_STATUS] == STATUS_FLAGGED) {
flaggedCells.add(cell);
}
}
return flaggedCells;
}
…into this …
public List<Cell> getFlaggedCells() {
List<Cell> flaggedCells = new ArrayList<>();
for (Cell cell : gameGrid.getCells()) {
if (cell.isFlagged()) {
flaggedCells.add(cell);
}
}
return flaggedCells;
}
…by encapsulating our array that models a Cell into a separate class called Cell. Naively, we could do this without changing the implementation:
public class Cell {
private int[] cellArray;
public static final int CELL_STATUS = 0,
CELL_ROW = 1,
CELL_COLUMN = 2,
CELL_IS_MINE = 3,
CELL_ADJACENCY = 4;
public static final int STATUS_HIDDEN = 0,
STATUS_REVEALED_NUMBER = 1,
STATUS_REVEALED_BLANK = 2,
STATUS_REVEALED_MINE = 3,
STATUS_FLAGGED = 4;
public boolean isFlagged() {
return cellArray[CELL_STATUS] == STATUS_FLAGGED;
}
}
However, after we have extracted the object to the class, it would then make sense for us to start refactoring this class to improve maintainability. The most logical start is turning the array into a set of fields:
public class Cell {
private enum CellStatus {
HIDDEN, NUMBER, BLANK, MINE, FLAGGED;
}
private CellStatus cellStatus;
private int rowNumber, columnNumber;
private boolean isMine;
private int adjacency;
public boolean isFlagged() {
return cellStatus == CellStatus.FLAGGED;
}
}
This refactoring is especially nifty, because we are only changing the implementation of Cell, not the interface (or behavior). This means that as we refactor this class, the function getFlaggedCells() is completely unaffected, because the behavior of the method isFlagged() doesn’t change!
This reveals a very important design benefit of abstraction that we will absolutely focus on soon!
Inline variable
Consider the following function:
public boolean canRegisterForAdvancedSoftwareDevelopment(Student student) {
if (student.getMajor == Majors.COMPUTER_SCIENCE && student.hasPassed("CS 3140")) {
return true;
} else {
return false;
}
}
This code makes a silly style mistake. The if-statement value:
student.getMajor == Majors.COMPUTER_SCIENCE && student.hasPassed("CS 3140")
…is already a boolean! This means our if-statement is completely unnecessary! So, we refactor to remove it:
public boolean canRegisterForAdvancedSoftwareDevelopment(Student student) {
return student.getMajor == Majors.COMPUTER_SCIENCE && student.hasPassed("CS 3140");
}
Abstract conditional logic
Consider the following function for calculating the price for an amusement park that charges different prices in the summer season and the winter season. This example is adapted from Refactoring Guru.
public double getCharge(Date date) {
if (date.before(SUMMER_START_DATE) || date.after(SUMMER_END_DATE)) {
return getWinterPrice();
} else {
return getSummerPrice();
}
}
This code is a bit tricky to read. The logic is simple enough (if the date is before the start of summer or after the end of summer, charge the winter price), but the code doesn’t read like “well-written prose.” We can refactor by encapsulating the if-statements boolean logic to a separate function. We can do this by highlighting the boolean logic, and then using Refactor->Extract Method:
public double getCharge(Date date) {
if (isNotSummer(date)) {
return getWinterPrice();
} else {
return getSummerPrice();
}
}
public boolean isNotSummer(Date date) {
return date.before(SUMMER_START_DATE) || date.after(SUMMER_END_DATE);
}
Invert boolean
This is still a bit odd. Consider the following two natural language sentences:
- “If it is not summer, charge the winter price. Otherwise, charge the summer price”
- “If it is summer, charge the summer price. Otherwise, charge the winter price”
Which is easier to read? Even though the only difference is the word “not”, the second sentence is much more natural to read. When reading the first sentence, you probably had to stop for a second and think. Even if it was just for a brief second, this is still too long! Well-written prose shouldn’t require pausing to try to understand such a simple idea!
Thus, we can rename our method isSummer with Refactor -> Invert Boolean on our method name, and we get:
public double getCharge(Date date) {
if (!isSummer(date)) {
return getWinterPrice();
} else {
return getSummerPrice();
}
}
public boolean isSummer(Date date) {
return !date.before(SUMMER_START_DATE) && !date.after(SUMMER_END_DATE);
}
Notice now our condition is !isSummer(date) and our isSummer function always returns the opposite of our previous boolean function isNotSummer. From there, if we left-click on the if-statement and then hit Alt + Enter:
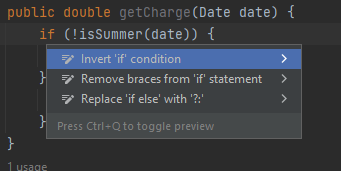
We can select “Invert ‘if’ condition”, and we get:
public double getCharge(Date date) {
if (isSummer(date)) {
return getSummerPrice();
} else {
return getWinterPrice();
}
}
Now this code reads as:
- “If it is summer, charge the summer price. Otherwise, charge the winter price!”
Replace Error Code with Exception
Error codes (return values pre-selected to indicate an error) are generally a bad idea. For example, say you implement your own square-root function.
public double squareRoot(double value) {
if (value < 0) {
return -1; //indicates square root of a negative number error
} else {
return Math.pow(value, 0.5);
}
}
This is a bad idea! This is because you are relying on whatever client that calls this function to always check the output for -1 to make sure they didn’t get an error. But can you really rely on this? Instead, it’s better to use an Exception:
public double squareRoot(double value) {
if (value < 0) {
throw new ArithmeticException("Error: Square Root of a negative number!");
} else {
return Math.pow(value, 0.5);
}
}
Now, you are ensuring the client has to handle incorrect usage of your squareRoot function, which is more likely to result in the client only using the function correctly (by checking to ensure the input is non-negative before calling squareRoot).
Replace Exception with Optionals
The Java Optional<T> class is useful for describing a value that may or may not be present.
Considering the following Java code:
public int max(List<Integer> integerList) {
if (integerList.isEmpty()) {
throw new IllegalArgumentException("Cannot get max of empty list!");
}
int maximum = integerList.get(0);
for (Integer value : integerList) {
if (value > maximum) {
maximum = value;
}
}
return maximum;
}
Here, a client would need to know not just that the function will take in a List<Integer> and return the max value as an int, but also that the client should be aware that this method throws an IllegalArgumentException if the input list is empty. That means, they have to handle both when a maximum is present and is not present. However, unless the documentation explicitly states this, a client may just assume the method works, and use it incorrectly. Optionals allow us to communicate syntactically that a method may either return a value or not.
public Optional<Integer> max(List<Integer> integerList) {
if (integerList.isEmpty()) {
return Optional.empty();
}
int maximum = integerList.get(0);
for (Integer value : integerList) {
if (value > maximum) {
maximum = value;
}
}
return Optional.of(new Integer(maximum));
}
Replace Null with Optionals
In the same way we can avoid Exceptions, we can also now avoid nulls. For instance:
public Student getStudentByComputingId(String computingId) {
for (Student student : studentList) {
if (student.getComputingID.equals(computingId)) {
return student;
}
}
return null;
}
…can instead become…
public Optional<Student> getStudentByComputingId(String computingId) {
for (Student student : studentList) {
if (student.getComputingID.equals(computingId)) {
return Optional.of(student);
}
}
return Optional.empty();
}
On the client side, the usage of this function may look like:
Optional<Student> optionalStudent = getStudentByComputingId("abc2def");
if (optionalStudent.isPresent()) {
Student student = optionalStudent.get();
//do something with student
} else {
//no student with that computingId exists
}
In effect, you are not just letting the client decide what to do if the function cannot return a meaningful value, you are syntactically forcing the client to decide what to do. This forces the client to consider what to do if the function doesn’t return anything, meaning they will not accidentally ignore a ‘null’ return.
Preserve Whole Object
Consider our building class from the Code Smells section on primitive obsession.
public class Building {
private String name;
private Address address;
private Coordinate coordinates;
//getters and setters
}
public class Address {
private String streetName;
private int streetNumber;
private int zipCode;
private String city;
private String state;
}
private class Coordinate {
private double latitude;
private double longitude;
}
Now imagine we had a function like:
getDistanceFromLocationTo(double latitude, double longitude)
If I wanted to find the distance from my location to, say, Rice Hall, I might run the code:
Building riceHall = buildingRepository.getBuilding("Rice Hall");
double riceLatitude = riceHall.getCoordinates.getLatitude();
double riceLongitude = riceHall.getCoordinates.getLongitude();
distanceScreen.display(getDistanceFromLocationTo(riceLatitude, riceLongitude));
But hang on a second! The entire reason we created the Coordinate class was to avoid primitive obsession, and here we are using primitives again! Instead, we should refactor the function:
getDistanceFromLocationTo(Coordinate destination)
And now our code is:
Building riceHall = buildingRepository.getBuilding("Rice Hall");
Coordinate riceCoordinates = riceHall.getCoordinates();
distanceScreen.display(getDistanceFromLocationTo(riceCoordinates));
This is better because the latter code does not rely on how the Coordinate class works! All we need to be aware of is that we have this class called Coordinate, and buildings have them, and we can get a distance from our current location to them. That is, we are now working only with the data-type Coordinate, and this code is agnostic to how Coordinate is actually implemented! If the Coordinate class interface or implementation changes, this code can remain unchanged!
Getters for mutables return copies
One concern in Java is that the most commonly used collections (ArrayList, HashMap, etc.) are all mutable. In fact, by default all objects are mutable. For example:
private class Coordinate {
private double latitude;
private double longitude;
//getters and setters for each field
}
This class is mutable. Assume that the class Building has the following getter:
public Coordinate getCoordinates() {
return coordinates;
}
Seems simple enough! What could go wrong?
A problem with this can be that sloppy programming can result in unintended state changes. For example, say I wanted to travel exactly .00002 degrees North of Rice Hall. I might write:
Building riceHall = buildingRepository.getBuilding("Rice Hall");
Coordinate riceCoordinates = riceHall.getCoordinates();
double riceLattitude = riceCoordinates.getLattitude();
riceCoordinates.setLattitude(riceLattitude + .00002);
Seem innocent? It isn’t! I just modified the memory of the object we are calling riceHall. Now, according to our buildingRepository, Rice Hall itself has been picked up and moved .00002 degrees North. This is because we modified the coordinates of Rice Hall itself, not a copy of the coordinates.
We can fix this by changing the getter function getCoordinates
public Coordinate getCoordinates() {
return new Coordinate(coordinates);
}
And then adding a Constructor to our coordinates class:
public Coordinate(Coordinate coordinate) {
this.latitude = coordinate.latitude;
this.longitude = coordinate.longitude;
}
This way, we are now returning a safe-copy Coordinate instance. It copies the values of the coordinates of Rice Hall, but is stored in a separate memory location. Therefore, we don’t have to worry about some rogue programming that causes Rice Hall to get up and walk away!
Java can also simplify this process with the interface Cloneable. For example:
public class Coordinate implements Cloneable {
@Override
public Object clone() throws CloneNotSupportedException {
return (Coordinate) super.clone();
}
}
…and instead use this clone() method in getCoordinates…
public Coordinate getCoordinates() {
return coordinates.clone()
}
Making copies of Collections
ArrayList is also mutable. Consider our MySortedList class we talked about in the testing unit. Below I show the constructor and the bad getter method.
public class MySortedList {
List<Integer> myList;
public MySortedList() {
myList = new ArrayList<>();
}
public boolean isEmpty() {
return myList.isEmpty();
}
//bad implementation
public List<Integer> getMyList() {
return myList;
}
}
Because myList is an ArrayList, it is mutable. This means if someone does:
List<Integer> myVariableList = mySortedListInstance.getMyList();
myVariableList.clear();
System.out.println(mySortedListInstance.getMyList().size());
This will always print zero, no matter how many values we had already added to mySortedListInstance. This is because the private mySortedListInstance.myList and our variable myVariableList are literally the same List. Anything we do to one affects the other.
Instead, we can take advantage of the fact that ArrayList has a nifty constructor that takes in an ArrayList. This constructor makes a copy of the ArrayList (same contents), but the copy is stored in a separate memory location, and is therefore safe.
public class MySortedList {
List<Integer> myList;
public MySortedList() {
myList = new ArrayList<>();
}
public boolean isEmpty() {
return myList.isEmpty();
}
//bad implementation
public List<Integer> getMyList() {
return new ArrayList<>(myList);
}
}
Now we are returning a safe copy with getMyList(), and we no longer have to worry about mutability issues.
In general, you should almost never return a reference to a mutable variable without a very good reason. If you don’t have an intentional very good reason, you should return a copy or clone.
A note on Refactoring Techniques
Some refactoring techniques are inherently opposites of one another. For instance:
These two refactors are opposite. That’s because each refactoring technique is a tool that solves a specific design or coding flaw. However, not all refactoring techniques are useful all the time. As you practice with refactoring and learn and study techniques, you will learn when to use which. Much of this comes from experience, but it requires staying vigilant and routinely making a habit of refactoring to clean your code.
Conclusion
Refactoring is a vital step in cleaning code! By changing the code’s implementation but maintaining its behavior, we can continuously ensure that our code stays clean throughout the development process!
There are a number of well established refactoring techniques and tools. IntelliJ, as well as most modern IDEs, has many of the tools entirely or partially automated! As such, it can dramatically improve the ease, speed, and accuracy of our refactoring.