Optimization Example
For this section, we will use this source code example at two ways to store a list of coordinates and calculate the total distance between them.
- Optimization Example
Point Class
For this code, we define the idea of a Point as two coordinates, and x and a y. I include the class Constructor and distance function below.
Point.java
public class Point {
private double x, y;
public Point(double x, double y) {
this.x = x;
this.y = y;
}
... //getters and setters
//Euclidean distance
public double distanceTo(Point point) {
double xDiff = this.getX() - point.getX();
double yDiff = this.getY() - point.getY();
return Math.sqrt(xDiff * xDiff + yDiff * yDiff);
}
}
Right out of the gate, this seems like an obvious way to represent points, as instances of a class Point. This would be easy to communicate, almost anyone looking at this class would understand what it does, the purpose of each method, and how it works.
We might also imagine a Path where we add Points and then can calculate a distance, draw it on a map, whatever. We can define the abstract interface of a Path below:
Path.java
public interface Path {
void add(double xCoordinate, double yCoordinate);
void add(Point point);
Point get(int index);
int size();
double totalDistance();
}
You’ll notice I have two different add methods, one which adds two coordinates as double values, and one that uses a Point instance. However, from the perspective of someone looking at this code, I would view these methods as doing the same thing, just with different inputs. This will, however, become relevant later, so put a mental pin there.
Let’s take a look as an “obvious” way to implement Path, using an ArrayList<Point>:
PointListPath.java
public class PointListPath implements Path {
private final List<Point> points;
public PointListPath(ArrayList<Point> points) {
this.points = points;
}
public PointListPath() {
points = new ArrayList<>();
}
public PointListPath(int initialCapacity) {
points = new ArrayList<>(initialCapacity);
}
@Override
public void add(double xCoordinate, double yCoordinate) {
points.add(new Point(xCoordinate, yCoordinate));
}
@Override
public void add(Point point) {
points.add(point);
}
@Override
public Point get(int index) {
return points.get(index);
}
@Override
public int size() {
return points.size();
}
@Override
public double totalDistance() {
double totalDistance = 0.0;
//Iterate through all but the last point, getting distance to next point
for (int i = 0; i < size()-1; i++) {
Point firstPoint = points.get(i);
Point secondPoint = points.get(i + 1);
totalDistance += firstPoint.distanceTo(secondPoint);
}
return totalDistance;
}
}
This seems a pretty straightforward implementation, letting the ArrayList<Point> handle most of the work, and using a simple accumulator for loop to get the distance. And this approach is fine! I would be happy to see a student write this code, especially with useful test-cases!
A quick note about the two Constructors: The ArrayList<E>() constructor, when creating an empty ArrayList, creates an array of size 10. Remember that if the ArrayList needs to handle more than 10 elements, it doubles the size of the underlying array. While this by itself is an O(n) operation, this still means that ArrayList.add still has an amortized constant runtime. That said, if we know how large we need our ArrayList to be ahead of time, we can get a small optimization by specifying the ArrayList<E>(int capacity) constructor, which defines the size of the initial array. If we pick a good number for the capacity based on our needs, we may never need to run this doubling array size operation. So I have already made some minor optimizations here.
Explaining the solution
The great part about Object-Oriented Programming is that it allows us to think of systems as objects interacting with one another, which lends itself to useful visual diagrams. For example, if I were explaining my code in PointListPath to a colleague, I might draw a diagram like this:
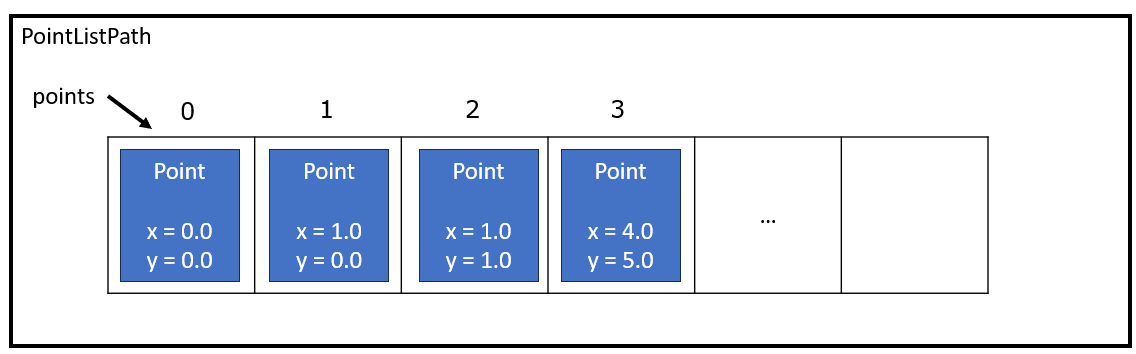
I visualize my Path containing an array that acts like a List, where each Point is stored at a particular index. I could use a whiteboard and explain how my add, get, and distance function works.
The problem is, this isn’t actually how Java works, or how most implementations of OOP work. The below diagram is a bit closer to how Java works
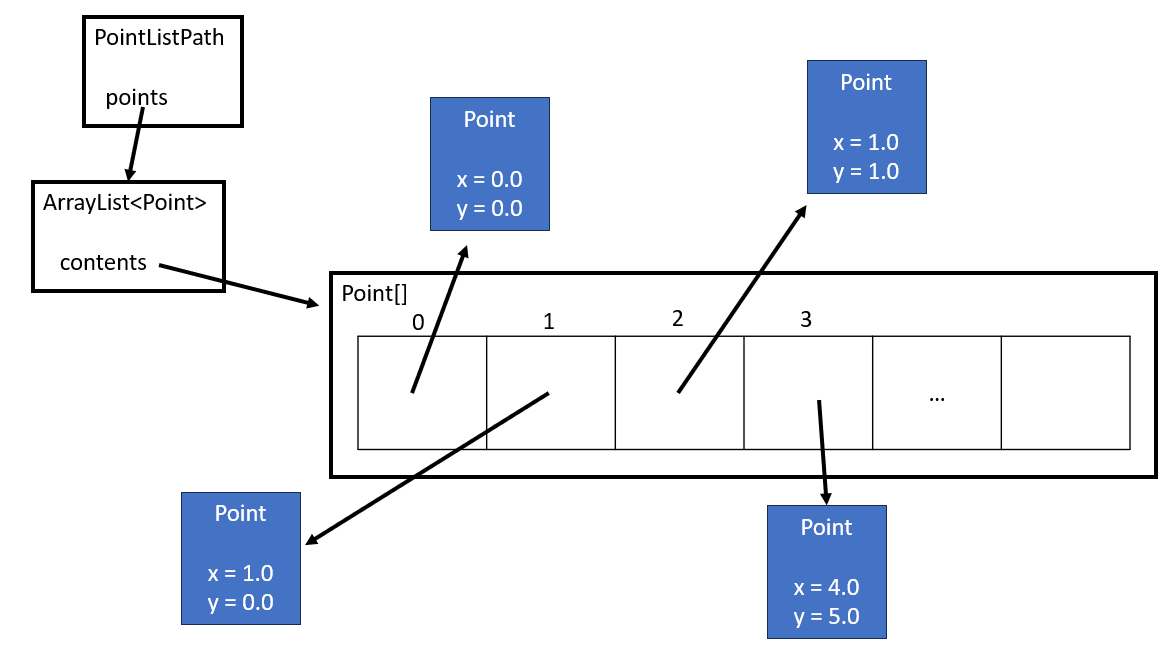
This diagram looks a bit more chaotic, with a lot more arrows. The key here is to illustrate that the Point objects are not actually inside the PointListPath object at all! For instance, if I had a PointListPath variable called path, it’s important to note that path is a reference to a PointListPath object in memory. That is path tells me where to look for its contents, not the contents themselves. So, something that seems simple, like getting the x coordinate of the point at index 2 involves the following:
1) Go to the memory address path references and access the reference value of points
2) Go to the memory address points references and access the reference value of contents plus 8 bytes (at least, typically 8 bytes, since each reference is 4 bytes “wide”)
3) Go to that memory address and access the double value of x
For step 2, it’s important to note that Arrays are stored sequentially, and for step 3, primitive data types are stored by value, not by reference. But the key takeaway is that even if we already have the reference to path, we still have to travel to three different memory addresses to get a single value.
Before you panic and burn down your code
Let me repeat what I said before: “And this approach is fine! I would be happy to see a student write this code…”. There is nothing wrong about this code. But what you should be aware of is that jumping around memory locations takes time! The rest of this unit is looking at a way to perform these operations faster (as well as how to measure this). That, however, doesn’t mean the above approach is bad.
Remember, premature optimization is the root of all evil!
Where this hurts performance
Arrays, even as part of ArrayLists, are fantastic for performance, because they store all contents sequentially in order. The fact that all the data is sequential makes iterating through it faster. Modern computers are optimized, using caching, to store sequential data directly in the CPU’s cache, instead of having to go to memory, which takes longer. This is the main reason why iterating through an ArrayList is substantially faster than iterating through a LinkedList, even though both are O(n).
Every time we call a constructor using new, the JRE allocates a location in memory for our data. However, the JRE is never the only process on your computer allocating memory! This means even if we create several points in a row in our code…
Point a = new Point(3, 5);
Point b = new Point(2, 7);
Point c = new Point(-3, 17);
…there’s no reason to believe that these objects are adjacent, or even near each other, in memory. This is a problem, because even if we create an array of Point, we are only allocating a sequential piece of memory to store reference, not the Point data! This means we always have to take at least one extra step in memory to access a value.
CoordinateArrayPath.java
One way to address this is to utilize arrays in a clever way to avoid the need for references. That is, store the values of x and y in the same array. I implement this idea in the below class. One fair note is that I didn’t implement this class to be “expandable”. This would be something I would do if I were implementing this class for real, but for the sake of this module, we’re just trying to demonstrate what an optimization may look like.
public class CoordinateArrayPath implements Path {
private final double[] pointArray;
private final int length;
private int currentSize;
public CoordinateArrayPath(int capacity) {
pointArray = new double[capacity * 2];
this.length = capacity;
this.currentSize = 0;
}
@Override
public void add(double xCoordinate, double yCoordinate) {
if (currentSize == length) {
throw new IllegalStateException("CoordinateArray is full and cannot add more points");
}
pointArray[currentSize * 2] = xCoordinate;
pointArray[currentSize * 2 + 1] = yCoordinate;
currentSize++;
}
@Override
public void add(Point point) {
add(point.getX(), point.getY());
}
@Override
public Point get(int index) {
if (index >= currentSize) {
throw new IndexOutOfBoundsException(String.format(
"index - %d is out of bounds for CoordinateArray of size - %d", index, currentSize));
}
double pointX = pointArray[2 * index];
double pointY = pointArray[2 * index + 1];
return new Point(pointX, pointY);
}
@Override
public int size() {
return currentSize;
}
@Override
public double totalDistance() {
double totalDistance = 0.0;
for (int i = 0; i < currentSize - 1; i++) {
double diffX = pointArray[2 * i] - pointArray[2 * i + 2];
double diffY = pointArray[2 * i + 1] - pointArray[2 * i + 3];
totalDistance += Math.sqrt(diffX * diffX + diffY * diffY);
}
return totalDistance;
}
}
To explain this, rather than storing a reference to a Point with an x and a y value at index i, I store the x value of 2 * i, and y at 2 * i + 1. So if the array is:
[3, 1, 4, 7, -5, 2]
This equates to the points:
(3, 1), (4, 7), (-5, 2)
This does make my logic a bit more complicated. Compare, for example, the distance functions between the two implementations:
PointListPath
public double totalDistance() {
double totalDistance = 0.0;
for (int i = 0; i < size()-1; i++) {
Point firstPoint = points.get(i);
Point secondPoint = points.get(i + 1);
totalDistance += firstPoint.distanceTo(secondPoint);
}
return totalDistance;
}
CoordinateArrayPath
public double totalDistance() {
double totalDistance = 0.0;
for (int i = 0; i < currentSize - 1; i++) {
double diffX = pointArray[2 * i] - pointArray[2 * i + 2];
double diffY = pointArray[2 * i + 1] - pointArray[2 * i + 3];
totalDistance += Math.sqrt(diffX * diffX + diffY * diffY);
}
return totalDistance;
}
Fundamentally these two pieces of code are doing the same thing. However, the first version uses an “Object-Oriented” approach (letting the ArrayList and Point classes do all the actual work). The second approach has code which is harder to understand at a glance (you have to understand the structure of the array, which is not trivially obvious when looking at this function), and the code is less DRY! We’re re-implementing Euclidean distance which exists elsewhere in our code base! From a “code quality” perspective, these both seem like red flags. However the advantage is that, because the entire contents of the path are in a single array, we will get the most benefit out of using the processor cache.
Benchmarking
My instinct is that the second approach will be computationally faster. But instincts can be wrong! So let’s measure! You can see the entire file by clicking here. Below I have a snippets of code to show me benchmarking two things:
1) Building the two Path implementations (using add) from a list of two double arrays (one for x coordinates, one for y coordinates).
2) Calculating the total distance of the path
To generate the random list of coordinates, I use:
private static double[] randomArray(int size) {
double[] array = new double[size];
for(int i = 0; i < size; i++) {
array[i] = Math.random();
}
return array;
}
To ensure my “experiment” is fair, both Path implementations will use the same x and y coordinate arrays. From the runBenchmark function:
double[] xCoordinates = randomArray(size);
double[] yCoordinates = randomArray(size);
printBenchMarkTimes(size, coordinateArray, xCoordinates, yCoordinates);
System.out.println("\t ---");
printBenchMarkTimes(size, pointArrayList, xCoordinates, yCoordinates);
From there, I intentionally wanted to separate the “building” time from the “distance calculation” time, measuring both times separately. The reasons for this will become clear in a bit. But here are the functions that calculate the time of each approach to “build” and run distance:
private static long calculateAddTime(int size, Path path, double[] xCoordinates, double[] yCoordinates) {
long startTimeMilliseconds = System.currentTimeMillis();
for (int i = 0; i < size; i++) {
path.add(xCoordinates[i], yCoordinates[i]);
}
long endTimeMilliseconds = System.currentTimeMillis();
return endTimeMilliseconds - startTimeMilliseconds;
}
private static long calculateDistanceTime(Path path) {
long startTimeNanoseconds = System.currentTimeMillis();
path.totalDistance();
long endTimeNanoseconds = System.currentTimeMillis();
return endTimeNanoseconds - startTimeNanoseconds;
}
The function System.currentTimeMillis(); gets your current System Time as milliseconds since January 1, 1970, midnight UTC. That sounds complicated, but we don’t actually have to worry about the true value, only the start time relative to the end time. We can get the time before running our code, and after running our code, which means the elapsed time is the ending time minus the start time. For this value, you don’t have to worry about timezones or anything weird like that, which is a good thing. It’s worth noting we use milliseconds, but given how fast modern computers are, we still need to use very large inputs before the time values are meaningful.
Distance Benchmark
For example, the below table shows the time, in milliseconds, to execute the distance function call on each list time. “Input Size” refers to the number of points in the Path. The next two columns show the elapsed time in milliseconds to complete the distance call for each data type. The inputs range from ten (10^1) to one hundred-million (10^8). Be aware that, especially on low input sizes, milliseconds are a coarse measure (for instance, 5 ms could really be anything from 5 to 5.9 milliseconds), so just because two times may be listed as zero ms, that doesn’t mean they were instantaneous. It just means on my hardware, the whole operation took less than 1 millisecond.
Remember, this is only the distance calculation, not the “build” time. We will look at that separately
| Input Size | PointListPath | CoordinateArrayPath |
|---|---|---|
| 10 | 0ms | 0ms |
| 100 | 0ms | 0ms |
| 1000 | 0ms | 0ms |
| 10000 | 1ms | 1ms |
| 100000 | 2ms | 2ms |
| 1000000 | 3ms | 2ms |
| 10000000 | 19ms | 15ms |
| 100000000 | 199ms | 153ms |
Looking at the last two rows in particular, it appears that CoordinateArrayPath is about 25% faster than PointListPath. Of course, these numbers are dependent on my own hardware, so things like having a smaller or large cache size on your processor could affect the relative difference. This is a significant performance increase…but don’t overly focus on the percentage value and lose focus of the actual raw time difference, which is 46ms. This means, per loop iteration, we are only saving, on average 0.46 nanoseconds per iteration. Because both implementations scale linearly, I’m confident this value wouldn’t change dramatically with larger input sizes, provided you actually have the memory available to run the application at that scale.
What even is 0.46 nanoseconds
This section is more written for my own enjoyment, and is about physics. You can skip it, as there’s nothing here about code writing or optimization.
Nanoseconds are a period of time that just doesn’t make sense to the human brain. It’s just too short a time to even think about. In fact, nanoseconds are so small, that even representing nanoseconds as a decimal is bizarre. It helps, weirdly, to think of nanoseconds as a distance traveled by light. This approach was popularized by Grace Hopper, who was among the first computer programmers ever and had a big role in developing the technologies that led to high-level programming languages.
For example, a light-second is roughly 186,000 miles (or if you don’t like freedom units, 300,000 kilometers). This means that if light could orbit the earth at light speed, in 1 second it would circle the planet roughly seven and a half times. So, 1 second = 7.5 earths long. A light-millisecond is roughly 186 miles, or for perspective, roughly the driving distance from Charlottesville VA to the Virginia Beach.
A light nanosecond is about 1 foot (well, precisely 0.983571 feet, but close enough). This that in the amount of time I save (0.46 ns) per iteration, light would only travel less than the height of a Starbucks venti-sized coffee cup. A fair note is that technically I’m referring to speed of light in the vacuum of space, and light is technically slower through air, but only barely. Still I felt I should say that before someone corrected me in an email.
As a side-note for transparency, I ran this code on my home desktop which at the time of this writing is 12th Gen Intel(R) Core(TM) i7-12700K with has a total cache size of 12MB, but it’s complicated by the multicore nature of the cache. In practice, the cache for a single core process (which this code is single threaded) is 1.5MB. If you don’t get the hardware stuff in the last paragraph, don’t worry about it. It’s just more to explain the experimental setup and how that could affect results.
Add Benchmark
Here are the timings for the calculateAddTime methods to be called at various sizes. Again, this is measuring the “building” of the object before we call distance, not including the distance call.
| Input Size | PointListPath | CoordinateArrayPath |
|---|---|---|
| 10 | 0ms | 0ms |
| 100 | 0ms | 0ms |
| 1000 | 0ms | 0ms |
| 10000 | 1ms | 1ms |
| 100000 | 2ms | 1ms |
| 1000000 | 14ms | 1ms |
| 10000000 | 144ms | 18ms |
| 100000000 | 1294ms | 166ms |
It may surprise you, but it turns out it actually takes longer for the Path objects to be “built” (using the add function) than it takes for distance to be calculated! This is true for both implementations! This may seem odd, since all we’re doing is copying data, and distance is doing math. But before I explain why, it’s worth noting just how slow building PointPathList (the ArrayList
It’s important to understand what the purpose of the Java new keyword is. new before the Constructor call communicates that, yes, this is a constructor call, but also it tells Java “I need memory for one of these”. So when I call new Point(x, y), I’m telling the JRE to go to the memory hardware and allocate enough space to store two doubles (for x and y), as well as any overhead storage the class needs for each Object. That process is actually quite slow compared to doing math, even something as computationally expensive as a square root operation. I do want to be clear that the only thing we are doing during the add phase for our ArrayList is adding. The ArrayList never needs to resize, as I initialize the ArrayList to the size of our input. It never has to “expand” (which would involve allocating new memory for a new array and copying references over). Yet even with that micro-optimization already there, it’s still slower because of all the Point objects.
In this situation, we can really notice a significant difference! Populating our ArrayList<Point> takes nearly 1.3 seconds. CoordinatedArray, since it allocates its array all at once, is over a full second faster. Put another way, that is slightly over 87% faster.
Total Runtimes
The table below combines the runtimes of both building the Path implementations and finding the total distance.
| Input Size | PointListPath | CoordinateArrayPath | SpeedUp |
|---|---|---|---|
| 10 | 0ms | 0ms | N/A |
| 100 | 0ms | 0ms | N/A |
| 1000 | 0ms | 0ms | N/A |
| 10000 | 1ms | 1ms | 0%* |
| 100000 | 4ms | 3ms | 75%* |
| 1000000 | 16ms | 4ms | 75%* |
| 10000000 | 163ms | 33ms | 80% |
| 100000000 | 1493ms | 319ms | 78% |
The speed-up values marked with an asterisk are dealing with small enough numbers of milliseconds I would inherently distrust them, or at least not make assumptions based on them. Simply put, execution “noise” (like my computer interrupting an execution to do some other task) could be large enough to throw these values off considerably. Once we have larger values, though, a pattern of 75%-80% faster seems clear.
Do we care NOW?!?!
So clearly, we care now, right! I mean, a 75% speedup! That’s huge!
Here’s the thing. I still don’t really care about this speed-up. Even knowing this difference is here, whenever I first write something like a Path implementation, I’m still going to implement it using an ArrayList<Point>. I know that may seem silly staring at a 75% speed-up, but keep in mind that this is only obviously when dealing with literally millions of Points worth of data. And even then, our total speed-up per Point is just 11.74 nanoseconds, or approximately the “light-height” of an African Elephant.
The simple truth is, I weigh that ~12 nanoseconds against the simplicity, readability, and testability of the code. PointListPath is simply easier to understand at a glance with no explanation. Now, I would still say CoordinateArrayPath is fairly simply, and the shared interface means it’s just as easy to use as PointListPath (that is, if I add resizability). But PointListPath is even simpler, even understandable-ier, if you’ll allow me to make up a stupid word. It’s “obvious” what everything in PointListPath is doing.
There’s value in having obvious code, because obvious code can be understood at a glance. Obvious code is easier to test and debug. Additionally, PointListPath is more modular, as the actual distance between two Point objects is handled by the Point class. Without a Point class, I necessarily have to reimplement the distance calculation between two points in CoordinateArrayPath.
Consider that the distance function is really doing two different things in CoordinateArrayPath
1) Calculating the distance between every adjacent pair of points
2) Calculating the sum of those distances and returning it
This isn’t modular! To show this, I could refactor the code as follows:
@Override
public double totalDistance() {
double totalDistance = 0.0;
for (int i = 0; i < currentSize - 1; i++) {
totalDistance += getDistance(
pointArray[2 * i], pointArray[2 * i + 1],
pointArray[2 * i + 2], pointArray[2 * i + 3]);
}
return totalDistance;
}
private double getDistance(double x1, double y1, double x2, double y2) {
double diffX = x1 - x2;
double diffY = y1 - y2;
return Math.sqrt(diffX * diffX + diffY * diffY);
}
Now, each function does one thing. totalDistance gets the sum of the individual distances, and distance gets the distance between two points defined as (x1, y1) and (x2, y2).
When would I care?
The truth is, in any practical use case for this code I can think of, that performance increase likely won’t mean much. I mean, who is actually going to use this API to calculate a path 100,000,000 coordinates long? How many people actually have that much data to begin with? And are any of them using my application? Or am I running this application on a shared server that is handling enough requests at one time that I actually run into time-sharing issues?
If I were maintain this application that is used by customers, and it became an issue where our customers were taxing our existing resources such that it was meaningfully affecting their satisfaction (i.e., customer wondering why the app is taking so long), THEN I would act. And, conveniently, because I hid my existing implementation behind an interface, I can simply reimplement that interface using arrays to get the speed-up needed. From there, the only code change I would need to make outside my new class is wherever the constructor for PointListPath is called.
At that point, this change potentially becomes the “low-hanging fruit”, at least on the side of building my Path, since the distance calculation really isn’t that much faster.
In short, I would prioritize code understandability and flexibility over performance until performance becomes a problem. While it is a fun intellectual exercise to optimize code, and it is a very valuable skill to practice, I view optimization like a fire alarm. When there’s a fire, you pull it. But otherwise, beyond making sure I’m using the right data structures and known algorithms for a particular problem, I don’t look for micro-optimizations unless I really need to.
Some optimization heuristics
Heuristics refers to “common rules that have worked well”. In optimization, we always want to measure to check if our changes actually make things better or worse:
1) Implement both approaches
2) Separate out the part you are benchmarking from the rest of the code as much as possible.
3) Test with increasing values of magnitude. Never rely on tests with “small” values. If dealing with a linear function, I’m usually measuring in the tens of thousands as a minimum.
4) Also consider the real usage of your system. Let’s say one approach is faster when dealing with input sizes of 10 million and greater, and a second approach is faster when dealing with less than that. Is your software actually going to deal with 10 million? This acts as sort of balance to Step 3.
5) Run multiple tests - a single test running on your computer could be thrown off by any number of unrelated background processes, never rely on a single test run
6) Vary the order - If testing A and B sequentially, test A then B, and then B then A, etc. This is because the order can actually affect the speed dramatically. For example, if your code is particularly intensive enough, it may lead to the processor heating up. Your computer may then “throttle” your processor (slow it down) to prevent overheating.
7) Related to 6) - when possible, especially with laptops, consider ambient temperature, as well as the surface your laptop is sitting on. If your laptop cannot dissipate heat effectively, your results are going to decrease in reliability and repeatability.